As part of my work in the CortexLab, an experimental neuroscience laboratory, we dealt with a large amount (1PB/year) of multimodal experimental data; keeping track of these data and their metadata is one of the biggest challenges in the field. Previous standardisation efforts, as well as current data organisation methods used in laboratories, have several drawbacks. Most recently, the Neurodata Without Borders project has worked to standardise a format for all experimental neurophysiology data. Alyx builds on this work and adds a number of key advantages.
Design
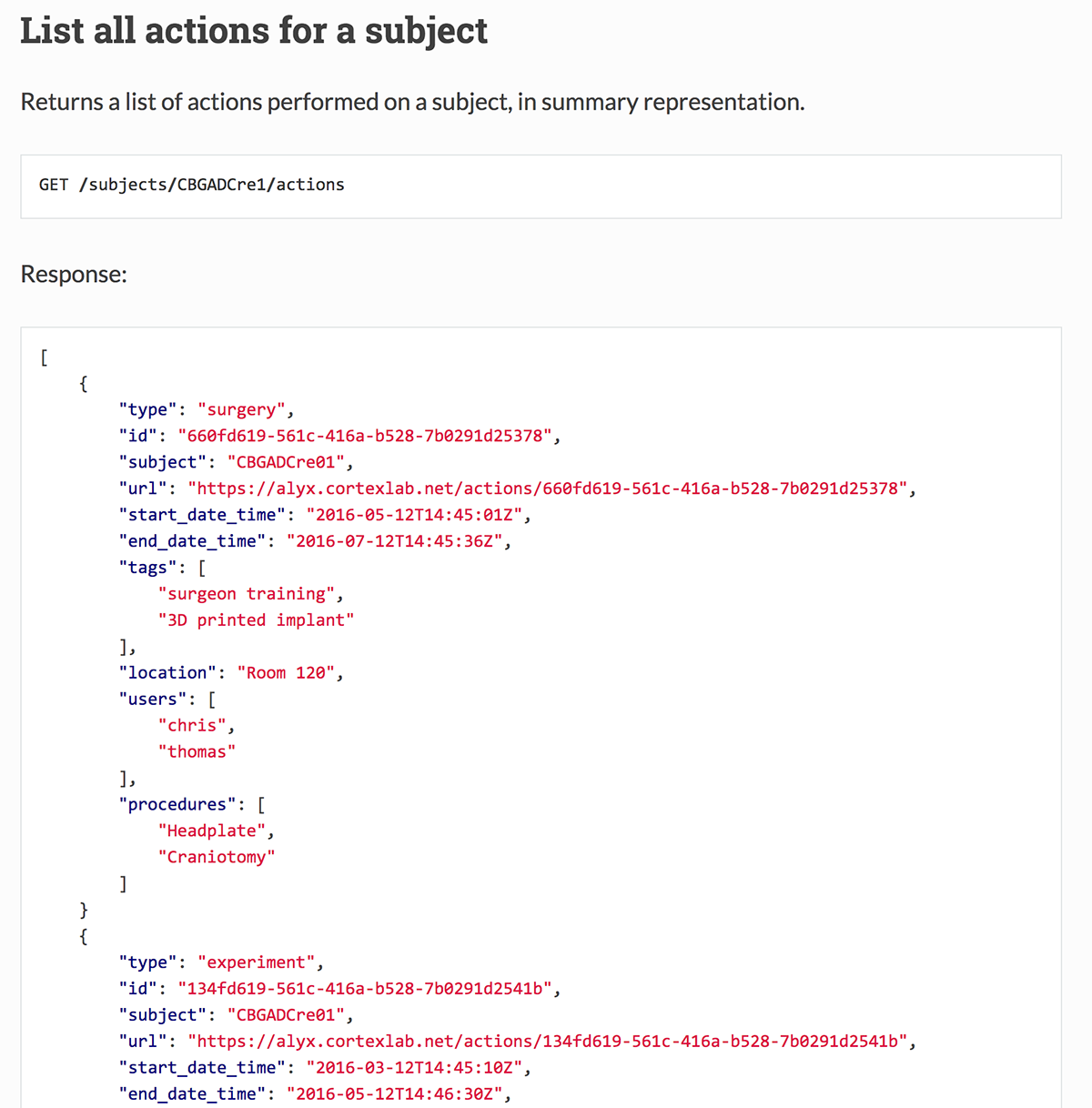
Alyx is a fast, flexible database designed for easy storage and retrieval of all data in an experimental neuroscience laboratory – from subject management through data acquisition, raw data file tracking and storage of metadata resulting from manual analysis.
Alyx is built using industry-standard tools (PostgreSQL 9.5 and Django 1.9) and designed to be interacted with using online webforms to enter and retrieve data manually, or with a documented and easy-to-use REST API programmatically (using built-in functions in MATLAB, Python, and most other modern programming languages, or command-line tools such as curl). It is easy to integrate with existing applications and allows for powerful queries to be performed to filter and return a specific subset of records in milliseconds. It requires minimal setup and can be hosted on your own internal server or in the cloud, for example with Amazon EC2.
Full documentation, as well as source code, can be found here on ReadTheDocs.
Roles
- Design, specification, implementation.
Kenneth Harris: co-design.
Year
2016-2017

{kind=link}